
 矚目客戶端
矚目客戶端 矚目小T
矚目小T 矚目大板
矚目大板 矚目會議室系統
矚目會議室系統 矚目直播
矚目直播
 多媒體通信平臺
多媒體通信平臺 多媒體通信終端
多媒體通信終端 多媒體通信軟件
多媒體通信軟件 網絡音頻處理器
網絡音頻處理器
 變電站智能巡檢機器人
變電站智能巡檢機器人 發電廠智能巡檢機器人
發電廠智能巡檢機器人 配電室智能巡檢機器人
配電室智能巡檢機器人 室內工業智能巡檢機器人
室內工業智能巡檢機器人 機器人遠程專家診斷協同平臺解決方案
機器人遠程專家診斷協同平臺解決方案





人工智能離現實有多近?來看美國人工智能年會的最近進展
時間:2017-02-13
文章轉載自硅谷密探,如有侵權請聯系刪除
這屆美國人工智能年會(AAAI),利用舉辦地在舊金山的地利,特別開設了為期一天的“AI in Practice”的討論,邀請了8家科技公司人工智能的技術主管,分享在各自領域的技術進展。

本期AI嚴肅說邀請了人工智能領域的資深投資人龍滔,結合會議的要點和工作的實踐來一起探討人工智能在業界的實踐。

從實際應用角度來看,關鍵性的應用幾乎不允許發生錯誤,一旦發生故障可能造成人員和財產損失,所以對整體系統包括硬件和軟件的可靠性要求非常高,實現難度也隨之加大。
而面向物理世界的應用,要求系統的魯棒性強,能夠處理物理世界的各種不確定性和復雜性。
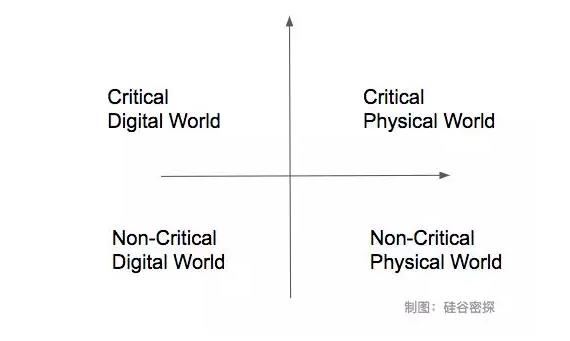
因此,從數字/物理世界、關鍵/非關鍵應用兩個維度來分析,人工智能的應用分成四大類,第一類是發生在物理世界的關鍵性應用,比如無人駕駛,畢竟人命關天。第二類是發生在數字世界的關鍵性應用,比如涉及到金融領域和計算機安全領域的問題,可能直接造成財產損失。第三類是發生在物理世界的非關鍵性應用,比如掃地機器人。第四類是發生在數字世界的非關鍵性應用,比如推薦系統。就商業應用路線而言,一般規律是從數字世界的非關鍵應用開始,逐步滲透到物理世界的關鍵應用。
發生在物理世界的關鍵性應用
總體而言,發生在物理世界的關鍵性應用技術難度非常大,比如高級別的無人駕駛,是需要長時間的培育和等待的領域。
“AI in Practice”的演講者之一,來自谷歌的Vincent Vanhoucke以及Waymo(谷歌的無人駕駛公司)的Dimitri Dolgov都分享了一些研發機器人和無人駕駛的經驗和教訓。
Vincent所帶領的Google Brain團隊目前工作主要集中在三個領域:語音識別、計算機視覺、機器人。而Dimitri引用了加利福尼亞車管局(DMV)提供了2016年關于無人駕駛里程及失靈(Disengagements)的數據(失靈時需要人類司機來駕駛),這個數據也基本驗證了無人駕駛的難度。
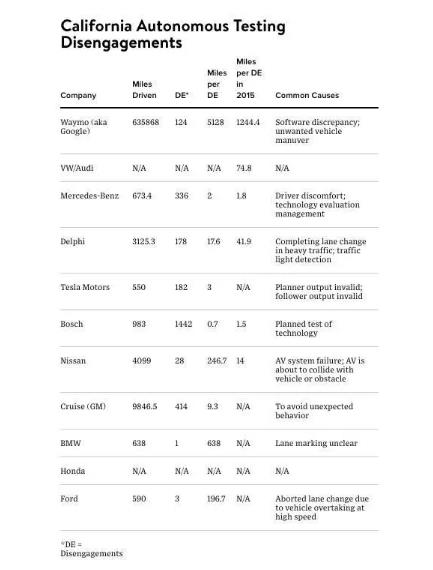
失靈比例最低的是谷歌,每5128英里失靈1次,可以想象的是,谷歌無人駕駛的測試數據依舊是在一定的限定環境下,特斯拉則是3英里就失靈1次。
即使是按照谷歌無人車現在這個數據,在駕駛如此高頻的情況,離完全的無人駕駛(Lever 4 or 5)還有很長一段距離。
按照長期以來的工業界的實踐,把可靠性從90%提升到99%,往往比0%提升到90%難很多,然而從99%提升到99.99%比從90%提升到99%更難,而我們對無人駕駛可靠性的要求可能要超過99.9999%。
實現固定場景的幾個英里的無人駕駛距離實現高級別無人駕駛還有漫長的一段路要走,此外無人駕駛汽車從設計到生產的周期還需要額外的3到5年的時間,該行業的創業公司的周期會非常長。不過值得一提的是,限定場景(比如高速公路)下的無人駕駛或者輔助駕駛依然很有意義。

(Vincent Vanhoucke)
Vincent Vanhoucke演講的最后一部分集中在機器人!他說之前還沒進入機器人領域時,看到DARPA挑戰賽中機器人的各種摔倒鏡頭會大笑,然后真正開始接觸之后,就再也笑不出來了。機器學習的研究人員會想當然地認為機器人已經大規模使用機器學習技術、想當然地認為機器人和環境狀態完全已知、想當然地認為樣本充足、想當然地認為計算機模擬十分逼近真實物理世界。從這個角度,機器人領域給機器學習提供了很多有意思的話題。
第一:如何協調感知和執行是機器人的關鍵。
機器人的感知是軟件層面,而執行則是機械層面。做算法的不懂機械,做機械的不懂軟件往往是業界共同面臨的問題。
第二,如何提高樣本的有效使用再次成為核心問題。
發生在物理世界的訓練樣本往往獲取非常困難,以機器人手臂隨機抓取物體的實驗為例,Google為了獲得訓練樣本,只能以14臺機械臂在那里日夜不停地獲得訓練數據。如何高效率的獲得樣本,或者是高效能的使用樣本,將是極其核心的問題。
第三:機器人領域涉及強化學習、無監督學習、主動學習。
對于機器人領域的核心技術強度學習,特別是深度強化學習(Deep Reinforce Learning),幾乎所有我們拜訪的工程師,包括Vincent一致認為技術實現的難度非常大。
第四:閉環控制系統對于改善性能極為必要。
第五:需要新的數據結構,用于表示運動學鏈接(Kinematic chain)、圖像的卷積、運動軌跡。在之后的問答環節,他對遷移學習抱有厚望。
老牌的IBM業務多元化、而且絕大部分是面向企業服務市場(to B)。因此,Michael Witbrock提出對于人工智能領域的研究路線更為系統、同時也更為傳統。
他提到對世界的大規模建模,由之前明確的、符號化的、分解的建模方式,逐漸融合隱形的、統計的建模方式。例如之前機器人動力學方程中對于摩擦力這類非線性變量的建模和求解時,難度就不小。

IBM 強調了符號主義的重要性,認為知識表達、邏輯在解決復雜問題中非常重要。
基于邏輯的傳統知識表示值得引起我們的重新思考(Rethink)。

IBM在此方面的研究優勢是既有硬件,又有軟件。在整個IBM的研究人員Michael Witbrock演講中,他很自豪地介紹IBM過去在人工智能領域取得的進展,并且已經廣泛部署到多個領域,其中有一項是在人力資源領域的應用。
對比一個國內的案例,某乳品巨頭的人力資源負責人在談到人工智能在人力資源領域的應用時不屑一顧地談到人力資源的工作富有人情味,冷冰冰的機器如何應對。其實,LinkedIn的職位招聘不也是人力資源的一部分嗎?傳統行業如何面對高科技的進步,被顛覆還是主動整合,看似簡單的答案要落到實地并不容易。
值得重視的是,隨著人工智能應用入侵傳統行業,通常需要對控制對象所處的物理環境建模,這一塊是比互聯網更廣闊的天地,機會更多,當然也更難。
發生在數字世界的非關鍵性應用
從實現難度而言,發生在數字世界的非關鍵性應用最容易發生,實際上推薦系統就是一個很好的例子,一方面大家對推薦商品的準確性相對寬容。
發生在數字世界的非關鍵性應用擠滿各種互聯網公司巨頭,創業公司在這個領域想有所作為也很難,或許還有垂直領域有些機會。而創業公司如何突破人才、數據、計算資源的局限,尋找生存空間值得進一步探討。
代表Quora出場的Xavier Amatriain恰好就回答了這個問題。Quora是家是中小型的創業公司,是美國的問答網站(類似于國內的知乎)。Quora只有85位技術工程師,其中僅僅兩位研究員。人才寥寥、計算存儲資源不多、數據也不是那么充足,
創業公司怎么能夠避免一些技術彎路,正確應用人工智能技術呢?Xavier總結了他這么多年在機器學習實際工作的一些教訓。
1. 更多的數據還是更好的算法?
Xavier認為更好的算法更為重要;
對于小公司而言,本身數據量就少,而獲得標記的數據更是需要額外的成本。小公司堆數據肯定是堆不過大公司,所以選擇把精力放在優化算法上往往比選擇把精力放在獲取數據上更高效
當然一方面小公司也需要不斷地積累數據。
2. 復雜模型還是簡單模型?
Xavier認為模型和特征選取需要匹配;
模型不是越復雜越好,在創業公司往往是不管黑貓白貓,能抓到老鼠就是好貓。根據界定的問題,選取與特征相匹配的模型。
3. 什么情景下用監督學習還是非監督學習?
Xavier認為非監督學習可以降低維度、并對特征做工程突破。在某些情況下,將監督學習和非監督學習結合,效果出奇的好;
4. 多種算法的組合還是單一算法?
Xavier提出應該盡可能使用組合算法,不同于強調原創性的學術研究,創業公司更需要“拿來主義”,只要能用上,多嘗試不同的算法組合來提高準確率是個明智的選擇。
5. 不要將一個模型的輸出作為另一系統的輸入
Xavier警告說這會是系統設計的噩夢。
發生在數字世界的關鍵性應用和發生在物理世界的非關鍵性應用
發生在數字世界的關鍵性應用和發生在物理世界的非關鍵應用對創業公司而言是機會比較多的領域。比如將人工智能用于金融領域和安全領域。又比如掃地或是玩具機器人是一個典型的發生在物理世界的非關鍵性應用。這兩個領域是創業公司最有機會的。
人工智能顛覆性的理論突破仍需等待
通過神經科學或是其他學科與計算科學交叉,尋找人工智能新理論的突破仍停留在理論研究階段。
雖然深度學習已經獲得不少進展,然而大家至今很多領域依舊是知其然而不知其所以然,而人工智能其實理論研究獲得的突破依舊。

(Gary Marcus)
對于現在基于概率和數理統計的深度學習而言,紐約大學神經科學教授Gary Marcus希望從神經生物學的角度尋找人工智能的突破。他剛剛加入新成立的Uber AI Lab。我們在此斷章取義地引用他的觀點,“目前對于人工智能最大的擔心是技術發展停滯不前”!這也是我們所擔心的。
在近幾年深度學習的浪潮中,人工智能領域的進展更多是工程推進,而不是理論突破,尤其是海量數據和超大規模的暴力計算。正如Peter Norvig曾經談到Google在人工智能的出色表現時,就評論到“我們沒有更好的算法,我們僅僅是有更多的數據”。
而對于通用人工智能(Artificial General Intelligence),Gary繼續批評過去幾十年徘徊不前。現階段的智能不能像人一樣閱讀、理解、推理,無人駕駛的安全也不足以讓人信服……
人工智能研究的道路依舊任重道遠!
這屆美國人工智能年會(AAAI),利用舉辦地在舊金山的地利,特別開設了為期一天的“AI in Practice”的討論,邀請了8家科技公司人工智能的技術主管,分享在各自領域的技術進展。
本期AI嚴肅說邀請了人工智能領域的資深投資人龍滔,結合會議的要點和工作的實踐來一起探討人工智能在業界的實踐。
從實際應用角度來看,關鍵性的應用幾乎不允許發生錯誤,一旦發生故障可能造成人員和財產損失,所以對整體系統包括硬件和軟件的可靠性要求非常高,實現難度也隨之加大。
而面向物理世界的應用,要求系統的魯棒性強,能夠處理物理世界的各種不確定性和復雜性。
因此,從數字/物理世界、關鍵/非關鍵應用兩個維度來分析,人工智能的應用分成四大類,第一類是發生在物理世界的關鍵性應用,比如無人駕駛,畢竟人命關天。第二類是發生在數字世界的關鍵性應用,比如涉及到金融領域和計算機安全領域的問題,可能直接造成財產損失。第三類是發生在物理世界的非關鍵性應用,比如掃地機器人。第四類是發生在數字世界的非關鍵性應用,比如推薦系統。就商業應用路線而言,一般規律是從數字世界的非關鍵應用開始,逐步滲透到物理世界的關鍵應用。
發生在物理世界的關鍵性應用
總體而言,發生在物理世界的關鍵性應用技術難度非常大,比如高級別的無人駕駛,是需要長時間的培育和等待的領域。
“AI in Practice”的演講者之一,來自谷歌的Vincent Vanhoucke以及Waymo(谷歌的無人駕駛公司)的Dimitri Dolgov都分享了一些研發機器人和無人駕駛的經驗和教訓。
Vincent所帶領的Google Brain團隊目前工作主要集中在三個領域:語音識別、計算機視覺、機器人。而Dimitri引用了加利福尼亞車管局(DMV)提供了2016年關于無人駕駛里程及失靈(Disengagements)的數據(失靈時需要人類司機來駕駛),這個數據也基本驗證了無人駕駛的難度。
失靈比例最低的是谷歌,每5128英里失靈1次,可以想象的是,谷歌無人駕駛的測試數據依舊是在一定的限定環境下,特斯拉則是3英里就失靈1次。
即使是按照谷歌無人車現在這個數據,在駕駛如此高頻的情況,離完全的無人駕駛(Lever 4 or 5)還有很長一段距離。
按照長期以來的工業界的實踐,把可靠性從90%提升到99%,往往比0%提升到90%難很多,然而從99%提升到99.99%比從90%提升到99%更難,而我們對無人駕駛可靠性的要求可能要超過99.9999%。
實現固定場景的幾個英里的無人駕駛距離實現高級別無人駕駛還有漫長的一段路要走,此外無人駕駛汽車從設計到生產的周期還需要額外的3到5年的時間,該行業的創業公司的周期會非常長。不過值得一提的是,限定場景(比如高速公路)下的無人駕駛或者輔助駕駛依然很有意義。
(Vincent Vanhoucke)
Vincent Vanhoucke演講的最后一部分集中在機器人!他說之前還沒進入機器人領域時,看到DARPA挑戰賽中機器人的各種摔倒鏡頭會大笑,然后真正開始接觸之后,就再也笑不出來了。機器學習的研究人員會想當然地認為機器人已經大規模使用機器學習技術、想當然地認為機器人和環境狀態完全已知、想當然地認為樣本充足、想當然地認為計算機模擬十分逼近真實物理世界。從這個角度,機器人領域給機器學習提供了很多有意思的話題。
第一:如何協調感知和執行是機器人的關鍵。
機器人的感知是軟件層面,而執行則是機械層面。做算法的不懂機械,做機械的不懂軟件往往是業界共同面臨的問題。
第二,如何提高樣本的有效使用再次成為核心問題。
發生在物理世界的訓練樣本往往獲取非常困難,以機器人手臂隨機抓取物體的實驗為例,Google為了獲得訓練樣本,只能以14臺機械臂在那里日夜不停地獲得訓練數據。如何高效率的獲得樣本,或者是高效能的使用樣本,將是極其核心的問題。
第三:機器人領域涉及強化學習、無監督學習、主動學習。
對于機器人領域的核心技術強度學習,特別是深度強化學習(Deep Reinforce Learning),幾乎所有我們拜訪的工程師,包括Vincent一致認為技術實現的難度非常大。
第四:閉環控制系統對于改善性能極為必要。
第五:需要新的數據結構,用于表示運動學鏈接(Kinematic chain)、圖像的卷積、運動軌跡。在之后的問答環節,他對遷移學習抱有厚望。
老牌的IBM業務多元化、而且絕大部分是面向企業服務市場(to B)。因此,Michael Witbrock提出對于人工智能領域的研究路線更為系統、同時也更為傳統。
他提到對世界的大規模建模,由之前明確的、符號化的、分解的建模方式,逐漸融合隱形的、統計的建模方式。例如之前機器人動力學方程中對于摩擦力這類非線性變量的建模和求解時,難度就不小。
IBM 強調了符號主義的重要性,認為知識表達、邏輯在解決復雜問題中非常重要。
基于邏輯的傳統知識表示值得引起我們的重新思考(Rethink)。
IBM在此方面的研究優勢是既有硬件,又有軟件。在整個IBM的研究人員Michael Witbrock演講中,他很自豪地介紹IBM過去在人工智能領域取得的進展,并且已經廣泛部署到多個領域,其中有一項是在人力資源領域的應用。
對比一個國內的案例,某乳品巨頭的人力資源負責人在談到人工智能在人力資源領域的應用時不屑一顧地談到人力資源的工作富有人情味,冷冰冰的機器如何應對。其實,LinkedIn的職位招聘不也是人力資源的一部分嗎?傳統行業如何面對高科技的進步,被顛覆還是主動整合,看似簡單的答案要落到實地并不容易。
值得重視的是,隨著人工智能應用入侵傳統行業,通常需要對控制對象所處的物理環境建模,這一塊是比互聯網更廣闊的天地,機會更多,當然也更難。
發生在數字世界的非關鍵性應用
從實現難度而言,發生在數字世界的非關鍵性應用最容易發生,實際上推薦系統就是一個很好的例子,一方面大家對推薦商品的準確性相對寬容。
發生在數字世界的非關鍵性應用擠滿各種互聯網公司巨頭,創業公司在這個領域想有所作為也很難,或許還有垂直領域有些機會。而創業公司如何突破人才、數據、計算資源的局限,尋找生存空間值得進一步探討。
代表Quora出場的Xavier Amatriain恰好就回答了這個問題。Quora是家是中小型的創業公司,是美國的問答網站(類似于國內的知乎)。Quora只有85位技術工程師,其中僅僅兩位研究員。人才寥寥、計算存儲資源不多、數據也不是那么充足,
創業公司怎么能夠避免一些技術彎路,正確應用人工智能技術呢?Xavier總結了他這么多年在機器學習實際工作的一些教訓。
1. 更多的數據還是更好的算法?
Xavier認為更好的算法更為重要;
對于小公司而言,本身數據量就少,而獲得標記的數據更是需要額外的成本。小公司堆數據肯定是堆不過大公司,所以選擇把精力放在優化算法上往往比選擇把精力放在獲取數據上更高效
當然一方面小公司也需要不斷地積累數據。
2. 復雜模型還是簡單模型?
Xavier認為模型和特征選取需要匹配;
模型不是越復雜越好,在創業公司往往是不管黑貓白貓,能抓到老鼠就是好貓。根據界定的問題,選取與特征相匹配的模型。
3. 什么情景下用監督學習還是非監督學習?
Xavier認為非監督學習可以降低維度、并對特征做工程突破。在某些情況下,將監督學習和非監督學習結合,效果出奇的好;
4. 多種算法的組合還是單一算法?
Xavier提出應該盡可能使用組合算法,不同于強調原創性的學術研究,創業公司更需要“拿來主義”,只要能用上,多嘗試不同的算法組合來提高準確率是個明智的選擇。
5. 不要將一個模型的輸出作為另一系統的輸入
Xavier警告說這會是系統設計的噩夢。
發生在數字世界的關鍵性應用和發生在物理世界的非關鍵性應用
發生在數字世界的關鍵性應用和發生在物理世界的非關鍵應用對創業公司而言是機會比較多的領域。比如將人工智能用于金融領域和安全領域。又比如掃地或是玩具機器人是一個典型的發生在物理世界的非關鍵性應用。這兩個領域是創業公司最有機會的。
人工智能顛覆性的理論突破仍需等待
通過神經科學或是其他學科與計算科學交叉,尋找人工智能新理論的突破仍停留在理論研究階段。
雖然深度學習已經獲得不少進展,然而大家至今很多領域依舊是知其然而不知其所以然,而人工智能其實理論研究獲得的突破依舊。
(Gary Marcus)
對于現在基于概率和數理統計的深度學習而言,紐約大學神經科學教授Gary Marcus希望從神經生物學的角度尋找人工智能的突破。他剛剛加入新成立的Uber AI Lab。我們在此斷章取義地引用他的觀點,“目前對于人工智能最大的擔心是技術發展停滯不前”!這也是我們所擔心的。
在近幾年深度學習的浪潮中,人工智能領域的進展更多是工程推進,而不是理論突破,尤其是海量數據和超大規模的暴力計算。正如Peter Norvig曾經談到Google在人工智能的出色表現時,就評論到“我們沒有更好的算法,我們僅僅是有更多的數據”。
而對于通用人工智能(Artificial General Intelligence),Gary繼續批評過去幾十年徘徊不前。現階段的智能不能像人一樣閱讀、理解、推理,無人駕駛的安全也不足以讓人信服……
人工智能研究的道路依舊任重道遠!



-
分享本文到:
-
關注隨銳:

微信掃描,獲取最新資訊 -
聯系我們:
如果您有任何問題或建議,
請與我們聯系:
suiruikeji@suirui.com
 掃碼關注微信眾公號
掃碼關注微信眾公號 抖音掃一掃 關注隨銳
抖音掃一掃 關注隨銳 China
China
